Domácí cvičení - Vizualizace dat
Úkol 1
Vytvořte sloupcový graf pro proměnnou Kategorizovaný index demokracie.
Řešení
countries %>% count(di_cat) %>%
ggplot(aes(x = di_cat, y = n)) + geom_col()
#Alternativne
qplot(x = di_cat, data = countries)Úkol 2
Přidejte do grafu z 1. úkolu nad každý sloupec popisek, vyjadřující počet zemí v dané kategorii. Popisky by měli být nad sloupci.
Řešení
countries %>% count(di_cat) %>%
ggplot(aes(x = di_cat, y = n, label = n)) +
geom_col() +
geom_text(nudge_y = 1)Úkol 3
Vytvořte boxploty, které budou vyjadřovat vztah mezi proměnnými Kategorizovaný index demokracie a Naděje na dožití.
Řešení
ggplot(aes(x = di_cat, y = life_exp), data = countries) + geom_boxplot()Úkol 4
Odfiltrujte kategorii NA z grafu z 2. úkolu a seřaďte boxploty do pořadí “Full democracy”, “Flawed democracy” a “Hybrid regime”.
Řešení
countries %>%
filter(!is.na(di_cat)) %>%
mutate(di_cat = fct_relevel(di_cat,
"Full democracy",
"Flawed democracy",
"Hybrid regime")) %>%
ggplot(aes(x = di_cat, y = life_exp)) +
geom_boxplot()Úkol 5
Vytvořte scatterplot pro proměnné Podíl lidí s vysokoškolským vzděláním a Naděje na dožití.
Řešení
ggplot(aes(x = uni_prc, y = life_exp), data = countries) + geom_point()Úkol 6
Ve grafu z 5. úkolu od sebe barevně odlište postsovětské a západní země a tvarem bodu od sebe odlište země spadající do různých kategorií Kategorizovaného indexu demokracie.
Řešení
ggplot(aes(x = uni_prc, y = life_exp, color = postsoviet, shape = di_cat), data = countries) + geom_point()Úkol 7
Replikujte následující graf (Budete potřebovat balíček scales):
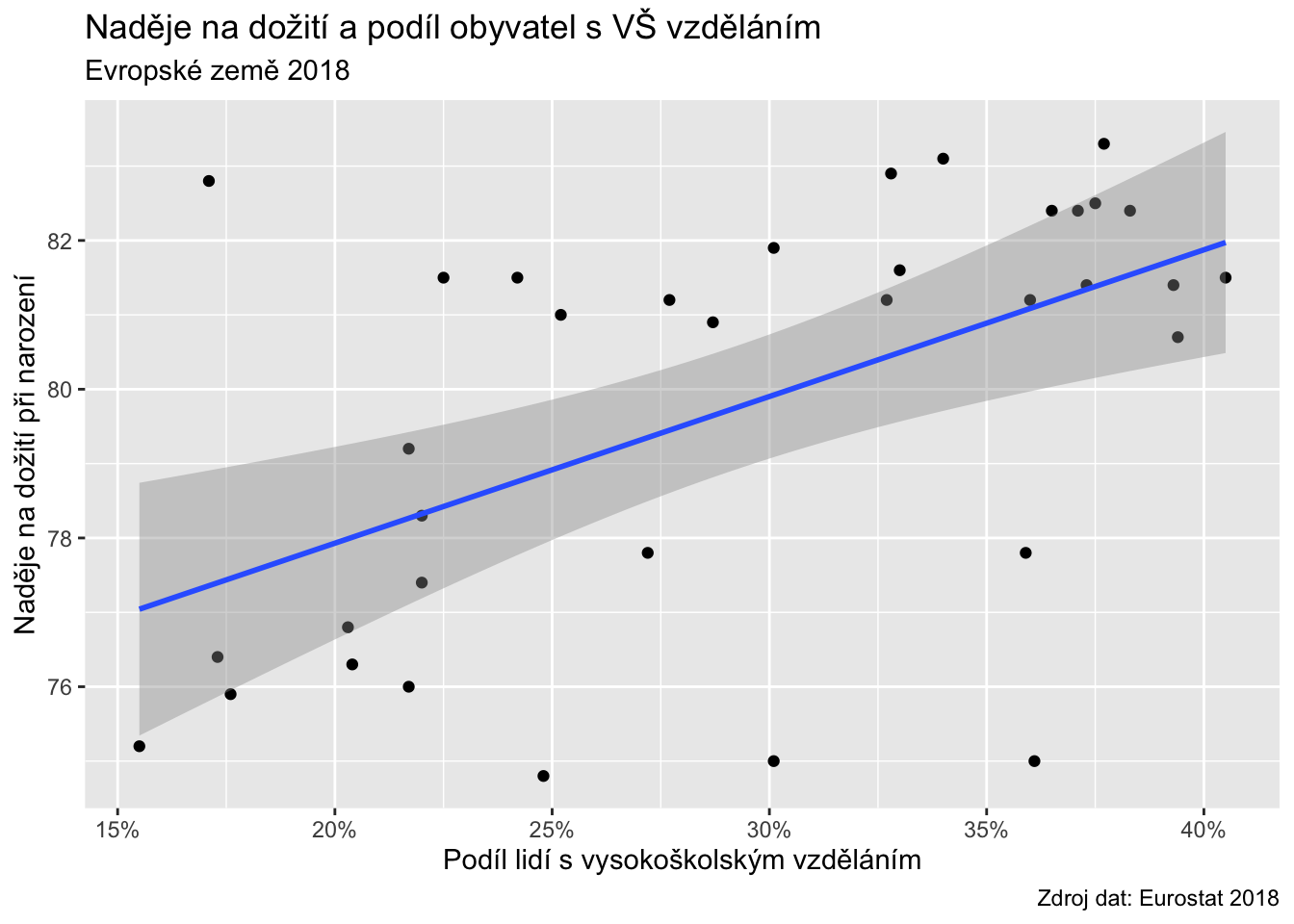
Řešení
library(scales)
ggplot(data = countries, aes(x = uni_prc, y = life_exp)) +
geom_point() +
geom_smooth(method = "lm") +
scale_x_continuous(labels = percent_format(1)) +
labs(x = "Podíl lidí s vysokoškolským vzděláním",
y = "Naděje na dožití při narození",
title = "Naděje na dožití a podíl obyvatel s VŠ vzděláním",
subtitle = "Evropské země 2018",
caption = "Zdroj dat: Eurostat 2018")Úkol 8
Replikujte následující graf:
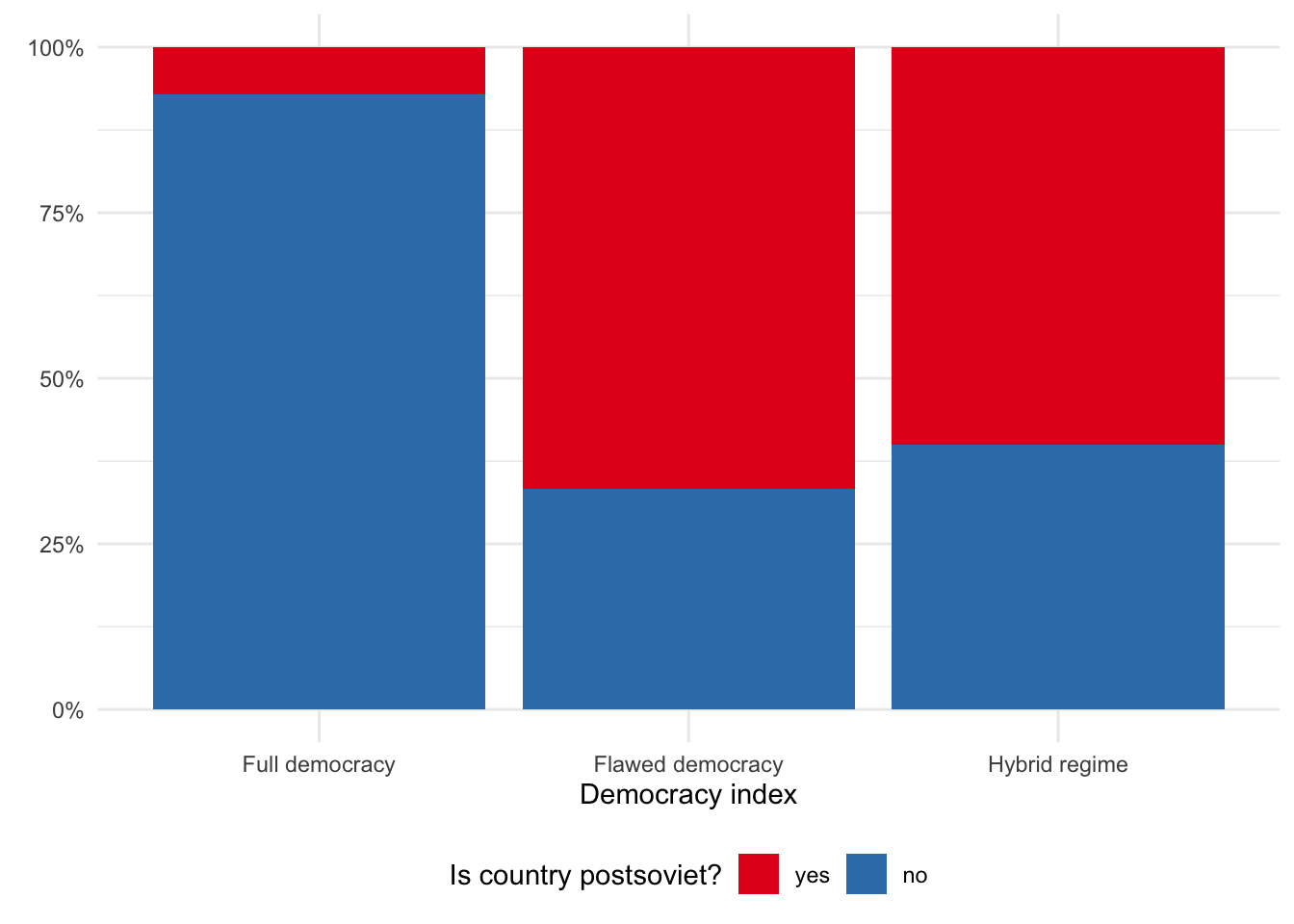
Několik tipů:
Budete potřebovat balíček
scales.Barvy pochází z brewer palety
Set1.Pozadí a celkový vzhled je možné měnit pomocí předpřipravených themes (např.
theme_bw(),theme_minimal(),…).
Řešení
countries %>%
filter(!is.na(di_cat)) %>%
count(di_cat, postsoviet) %>%
mutate(postsoviet = fct_rev(postsoviet),
di_cat = fct_relevel(di_cat, "Full democracy", "Flawed democracy", "Hybrid regime")) %>%
ggplot(aes(x = di_cat, y = n, fill = postsoviet)) +
geom_col(position = "fill") +
scale_fill_brewer(palette = "Set1") +
scale_y_continuous(labels = percent_format(accuracy = 1)) +
labs(x = "Democracy index", y = element_blank(), fill = "Is country postsoviet?") +
theme_minimal() +
theme(legend.position = "bottom")Úkol 9
Vytvořte si simulovaná data pomocí následujícího skriptu:
likert = c("Spokojen", "Spíše spokojen", "Spíše nespokojen", "Nespokojen")
set.seed(123)
spokojenost = data.frame(spokojenst_prace = sample(likert, size = 100,
replace = TRUE,
prob = c(0.2, 0.5, 0.3, 0.1)),
spokojenost_pratele = sample(likert, size = 100,
replace = TRUE,
prob = c(0.3, 0.5, 0.2, 0.1)),
spokojenost_parner = sample(likert, size = 100,
replace = TRUE,
prob = c(0.5, 0.1, 0.3, 0.1)),
spokojenost_rodina = sample(likert, size = 100,
replace = TRUE,
prob = c(0.1, 0.3, 0.2, 0.5)) )A replikujte následující graf:
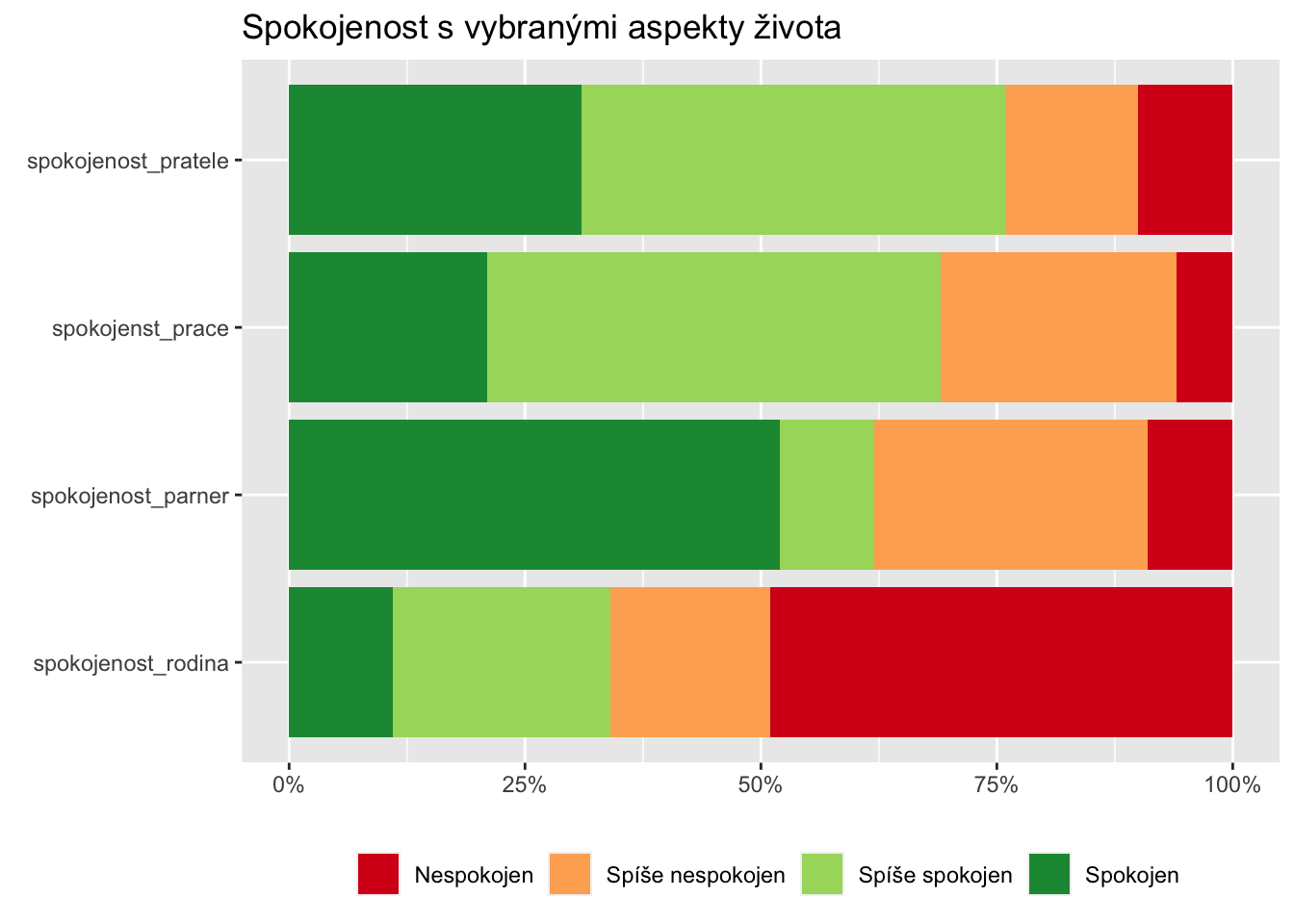
Několik tipů:
Budete potřebovat balíček scales.
Barvy pochází z brewer palety. Přehled palet najdete pomocí funkce
display.brewer.all()z balíčkuRColorBrewer.
Řešení
spokojenost %>%
pivot_longer(cols = everything()) %>%
count(name, value) %>%
group_by(name) %>%
mutate(trust = sum(n[value %in% c("Spokojen","Spíše spokojen")] )) %>%
ungroup() %>%
mutate(name = fct_reorder(name, trust)) %>%
ggplot(aes(x = n, y = name, fill = value)) +
geom_col(position = "fill") +
labs(x = element_blank(),
y = element_blank(),
fill = element_blank(),
title = "Spokojenost s vybranými aspekty života") +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
scale_fill_brewer(palette = "RdYlGn") +
theme(legend.position = "bottom")