countries %>%
count(postsoviet) %>%
ggplot(aes(x = 1, y = n, fill = postsoviet)) +
geom_col(position = "stack")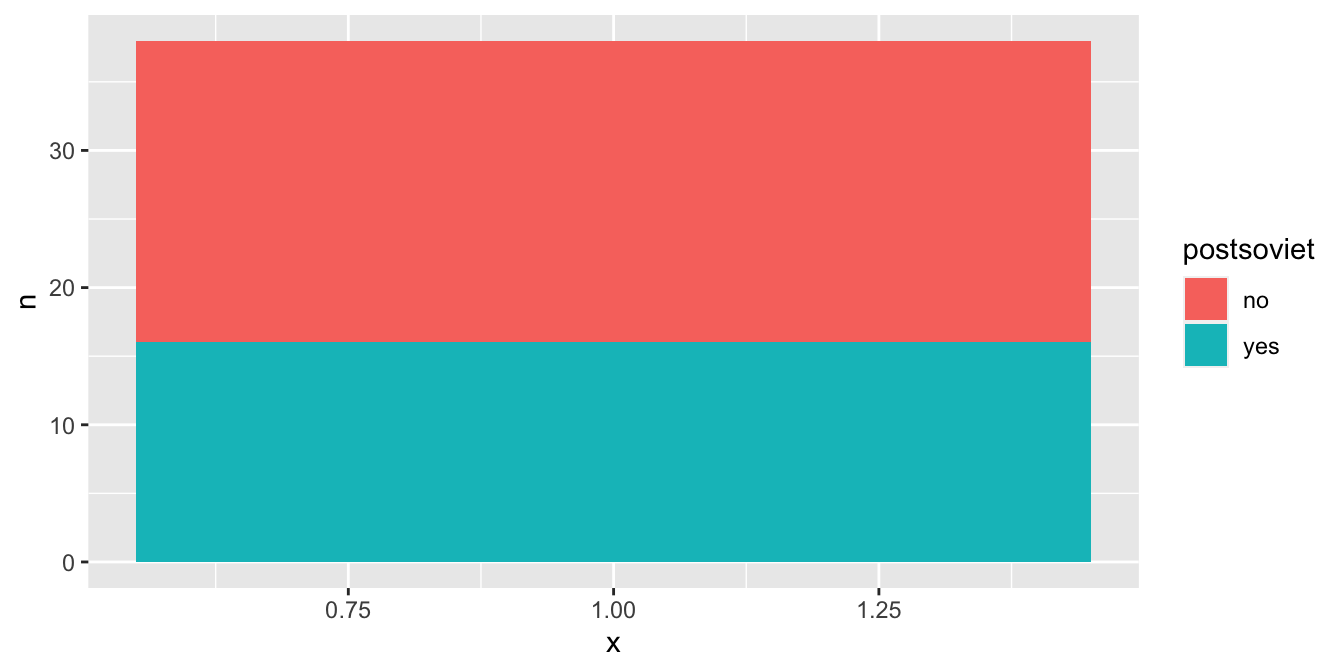
Předchozí kapitoly byly věnovány základům práce s balíčkem ggplot2. V této kapitole si ukážeme příklady pokročilejších technik, které při vizualizaci dat můžeme využít.
Většina grafů využívá karteziánské koordináty - objekty v grafu jsou mapované na horizontální a vertikální osu. Čas od času se ovšem vyplatí využít jiný systém. Jedním z nejpopulárnějších jsou polární koordináty.
Přestože si to možná neuvědomujeme, každý z nás se již s polárními koordináty setkal. Slouží k vytváření koláčových grafů, které nejsou ničím jiným, než stočenými skládánými sloupcovými grafy. Začněme vytvořením skládaného sloupcového grafu:
countries %>%
count(postsoviet) %>%
ggplot(aes(x = 1, y = n, fill = postsoviet)) +
geom_col(position = "stack")
Nyní jen stači použít funkci coord_polar() pro aplikace polárních koordinátů. Argumentem theta určíme, kterou z os “obtočíme” kolem středu grafu:
countries %>%
count(postsoviet) %>%
ggplot(aes(x = 1, y = n, fill = postsoviet)) +
geom_col(position = "stack") +
coord_polar(theta = "y")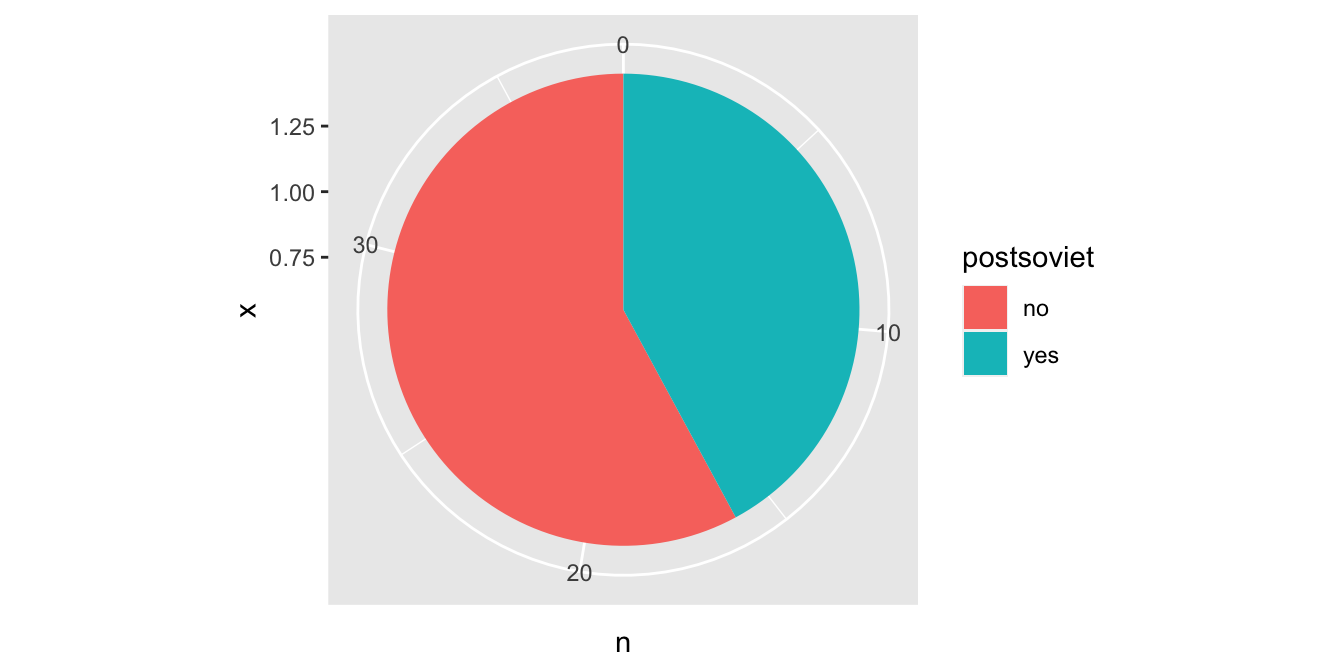
A je to, koláčový graf je hotový! Obdobným způsobem je možné vytvářet i další varianty. Například takzvaný donut chart, tedy koláčový graf s dírou ve středu, vytvoříme jednoduše tak, že necháme prostor mezi začátkem horizontální osy a sloupcem:
countries %>%
count(postsoviet) %>%
ggplot(aes(x = 1, y = n, fill = postsoviet)) +
geom_col() +
scale_x_continuous(limits = c(0, NA)) +
coord_polar(theta = "y")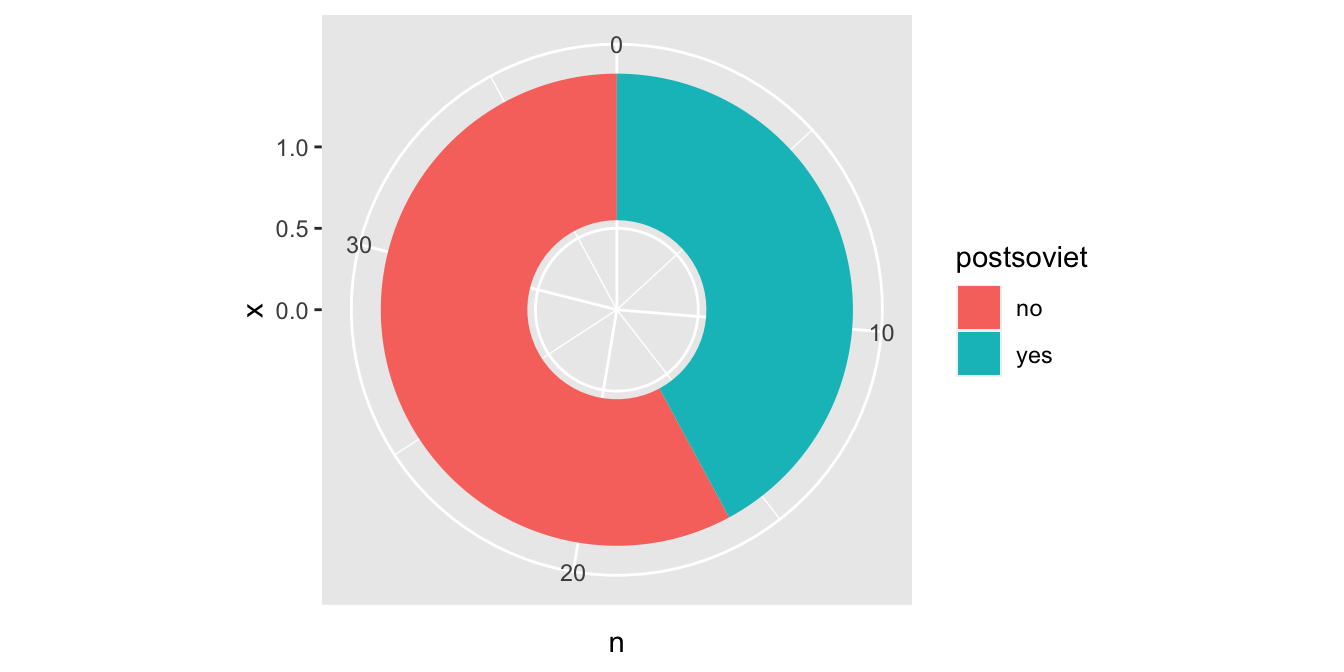
Mnoho komplexních grafů je možné vytvořit kombinací několika vrstev geomů. K tomu nám pomůže fakt, že každá vrstva ggplot2 grafů může mít svůj vlastní zdroj dat a své vlastní mapování. Následující graf se nazývá barbell chart a využívá se pro srovnání zpravidla dvou skupin napříč několika proměnnými. Přestože tento graf může na první pohled vypadat komplikovaně, jedná s jen o dvě sady bodů spojené úsečkou.
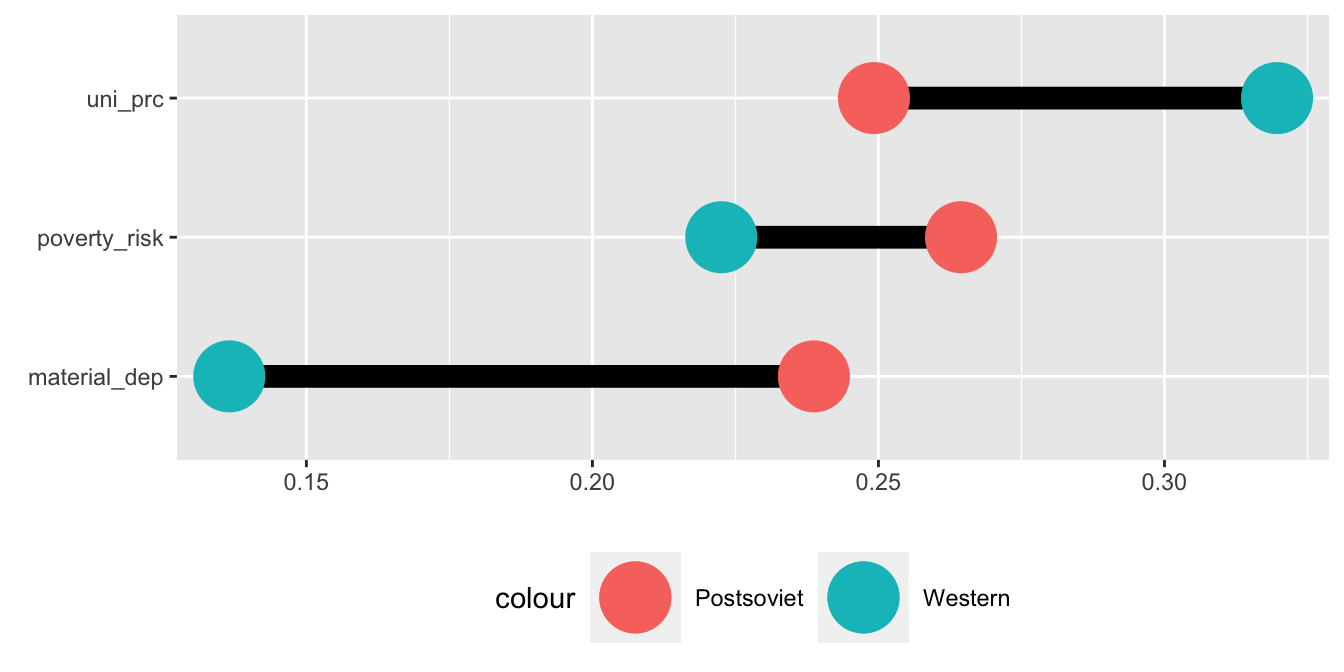
NULLZačněme přípravou dat. Pro každou ze skupin proměnné postsoviet spočítáme průměr proměnných material_dep, poverty_risk a uni_prc. Data poté převedeme do dlouhého formátu:
countries %>%
group_by(postsoviet) %>%
summarise(across(.cols = c(material_dep, poverty_risk, uni_prc),
.fns = mean, na.rm = TRUE)) %>%
pivot_longer(cols = -postsoviet)# A tibble: 6 × 3
postsoviet name value
<chr> <chr> <dbl>
1 no material_dep 0.137
2 no poverty_risk 0.223
3 no uni_prc 0.320
4 yes material_dep 0.239
5 yes poverty_risk 0.264
6 yes uni_prc 0.249Druhým krokem je vytvořením grafu. Nejdříve využijeme funkce geom_line() pro vytvoření úsečky spojující obě skupiny zemí. Poté přidámé další vrstu grafu, tentokrát za pomoci funkce geom_point(). Tou vytvoříme body reprezentující oba typy zemí. Všimněme si, že geom_point() má svůj vlastní argument mapping. To proto, že chceme barevně rozlišit pouze body, ne úsečky, které je spojují. Díky tomu, že každý geom je možné napojit na jiný zdroj dat, máme velkou kontrolu nad finálním vzhledem grafu.
countries %>%
group_by(postsoviet) %>%
summarise(across(.cols = c(material_dep, poverty_risk, uni_prc),
.fns = mean, na.rm = TRUE)) %>%
pivot_longer(cols = -postsoviet) |>
ggplot(mapping = aes(x = value, y = name)) +
geom_line() +
geom_point(mapping = aes(color = postsoviet), size = 3)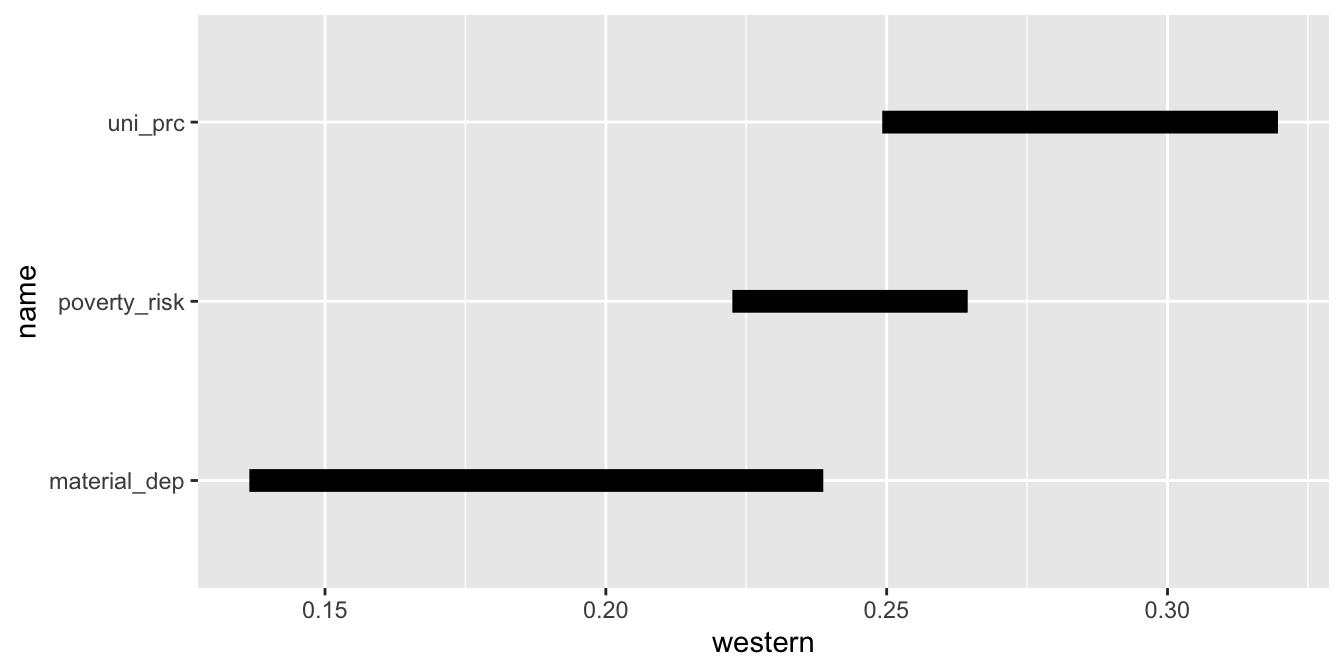
V posledním kroce už jen stačí upravit a lehce doladit vzhled grafu. Hned je patrné, že postsovětské země vedou nad západními v počtu lidí ohrožených chudobou i materiální deprivací a naopak zaostávájí v počtu vysokoškoláků.
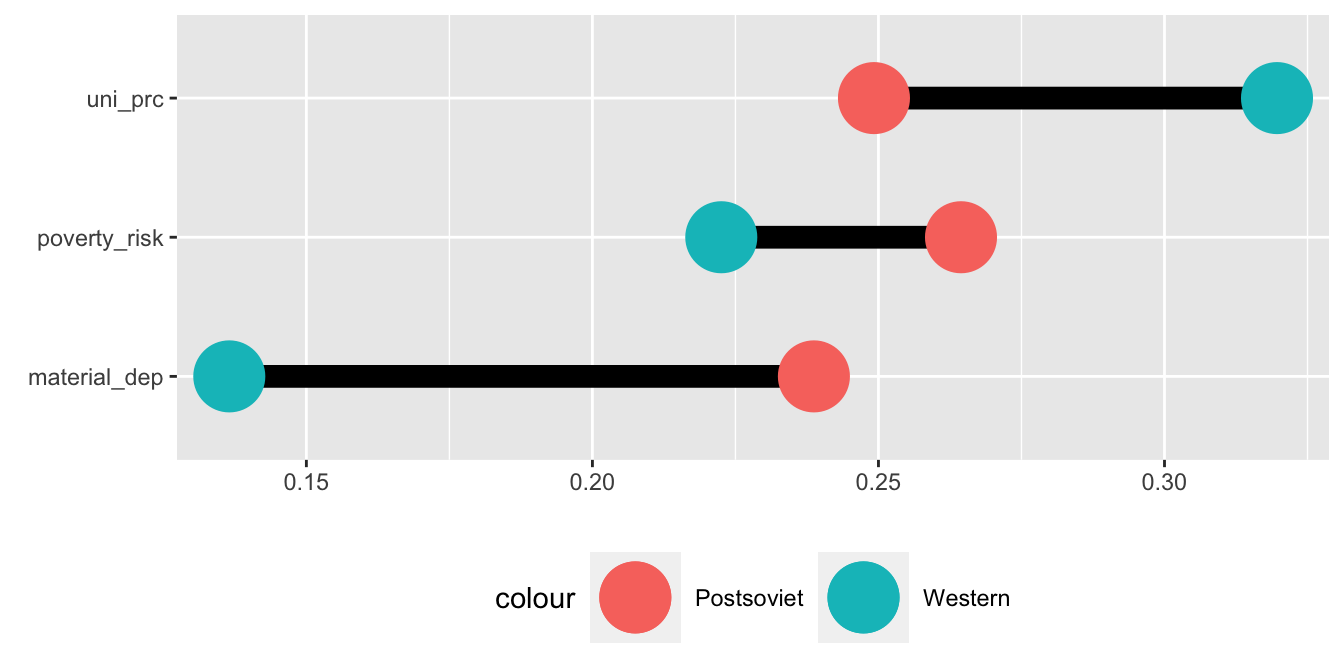
Jeden graf může být vytvořen z několika dataframů. To se může hodit například v situacích, kdy chceme vytvořit graf obsahující facety zvýrazňující určitou skupinu dat:
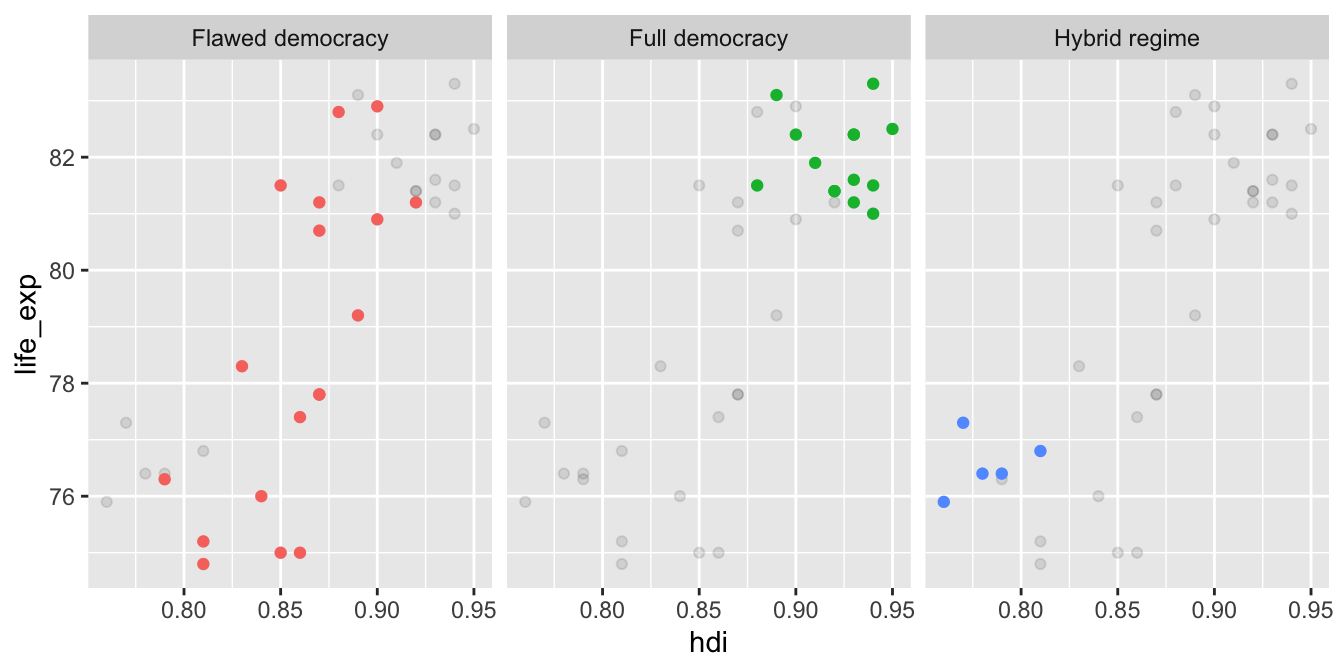
Graf výše využívá faktu, že facety recyklují všechna pozorovaní, které nepatří do jedné konkrétní facety. Začneme tím, že vytvoříme nový dataframe countries2, který je téměř stejný jako countries, ale neobsahuje proměnnou di_cat (a rovnou se zbavíme chybějících hodnot):
countries2 <- countries %>%
filter(!is.na(di_cat)) %>%
select(-di_cat)Poté vytvoříme bodový graf pro proměnné hdi a life_exp rozdělený do facet podle proměnné di_cat. Zdroj dat ale nespecifikujeme uvnitř funkce ggplot(), ale až ve funkci geom_point(). Jako zdroj dat použijeme countries2. Protože tento dataframe neobsahuje facetovou proměnnou, budou všechny body zobrazeny ve všech facetech:
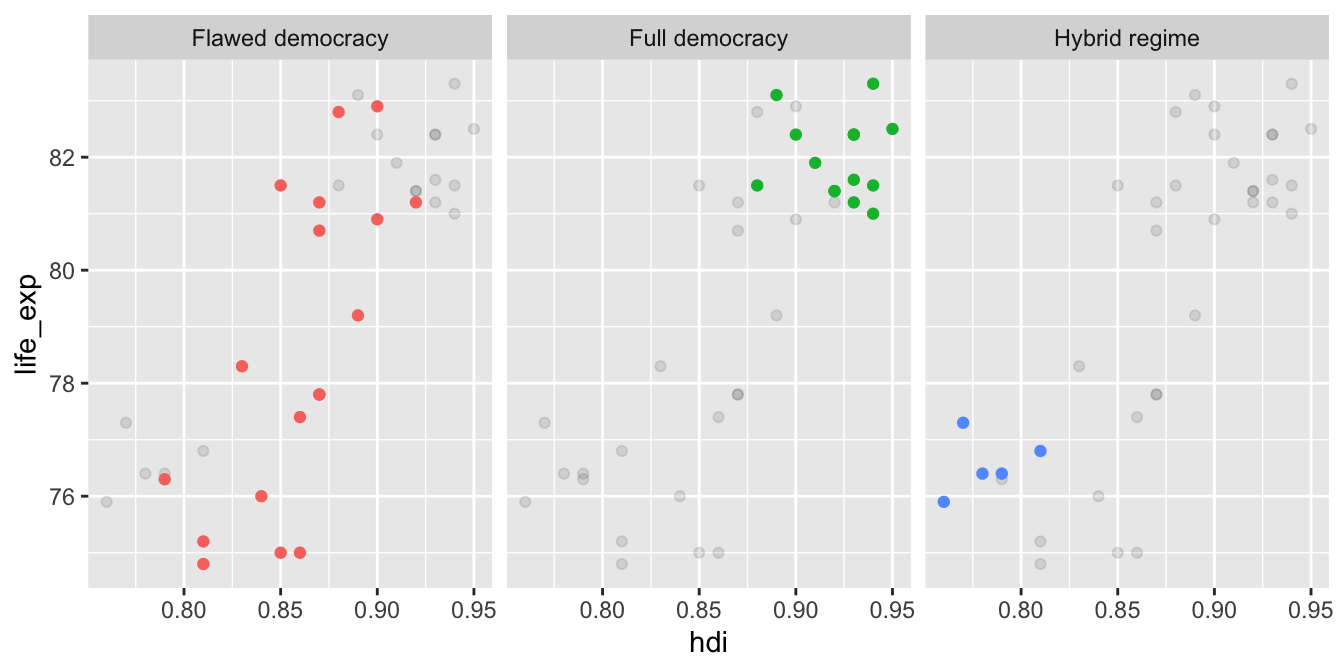
countries %>%
filter(!is.na(di_cat)) %>%
ggplot(aes(x = hdi, y = life_exp)) +
geom_point(data = countries2, alpha = 0.1) +
facet_wrap(~di_cat)
Nyní přidáme druhou vrstvu bodů, tentokrát založenou na dataframu countries. Tento dataframe již facetovou proměnnou obsahuje, takže body budou zobrazeny jen pro relevantní facetu. Také rovnou skryjeme nepotřebnou legendu:
countries %>%
filter(!is.na(di_cat)) %>%
ggplot(aes(x = hdi, y = life_exp)) +
geom_point(data = countries2, alpha = 0.1) +
facet_wrap(~di_cat) +
geom_point(aes(color = di_cat), show.legend = FALSE)