nazev_funkce <- function(argument1, argument2, ...) {
# Definice funkce
}28 Vlastní funkce
R nabízí širokou nabídku funkcí pro analýzu dat. Tuto nabídku je možné dále rozšířit balíčky jako tidyverse. Čas od času se ale dostaneme do situace, kdy nám žádná z předpřipravených funkcí nestačí. Naštěstí pro nás nám R umožňuje jednoduše vytvářet funkce vlastní . Obecná poučka říká, že každý kus kódu, který se v našem skriptu opakuje víc než dvakrát, by měl být nahrazen funkcí. Tím si nejen ušetříme čas při analýze, ale také snížíme šanci, že se někde v kódu upíšeme a uděláme chybu.
Funkce v R jsou objekty a je tedy možné je vytvářet stejným způsobem, jakým bychom vytvořili například dataframe. Vlastní funkci vytvoříme pomocí funkce function(), následované složenými závorkymi. Uvnitř jednoduchých závorek můžeme definovat jednotlivé argumenty, uvnitř složených závorek poté definujeme funkci samotnou. Obecně vypadá definice nové funkce takto:
Vytváření funkcí si ukážeme na několika případech.
28.1 Příklady vlastních funkcí
28.1.1 Počet chybějících hodnot v proměnné
Jednou z častých operací, kterou v rámci analýzy budeme provádět, je počítat množství chybějících hodnot v proměnné. Poněkud překvapivě, R neobsahuje funkci, která by pro nás chybějící hodnoty spočítala. Musíme proto využít kombinace funkcí is.na() a sum(). Například pro spočítáná chybějících hodnot u proměnné gdp:
sum(is.na(countries$gdp))[1] 3Pro pohodlnost si vytvoříme vlastní funkci jménem count_na(). Pro začátek bude mít tato funkce jeden argument, a to proměnnou, pro které chceme počet chybějících hodnot spočítat:
count_na <- function(x) {
na_count <- sum(is.na(x))
return(na_count)
}Útroby této funkce vypadají podobně jako předchozí kód, jen název proměnné je nahrazen generickým argumentem x. Výsledek je uložený do objektu na_count (existujícím pouze uvnitř této funkce). Spočítanou hodnotu poté exportujeme z naší funkce pomocí return(). Takto vytvořenou funkci můžeme využívat tak, jak jsme zvyklí:
countries %>%
summarise(across(.cols = everything(),
.fns = count_na)) %>%
pivot_longer(cols = everything(),
values_to = "missings_count")# A tibble: 17 × 2
name missings_count
<chr> <int>
1 country 0
2 code 0
3 gdp 3
4 population 1
5 area 0
6 eu_member 0
7 postsoviet 0
8 life_exp 1
9 uni_prc 3
10 poverty_risk 5
11 material_dep 5
12 hdi 0
13 foundation_date 0
14 maj_belief 0
15 dem_index 1
16 di_cat 1
17 hd_title_name 0Naše funkce spočítá absolutní frekvenci chybějících hodnot v proměnné. Co kdybychom ale chtěli relativní frekvenci, tedy podíl chybějících hodnot z celkového množství pozorování? Toho docílíme tak, že naši funkci rozšíříme o další argument, relative. Pokud bude hodnota tohoto argumentu TRUE, bude počet chybějících hodnot vydělen počtem všech hodnot v proměnné.
count_na <- function(x, relative = FALSE) {
na_count <- sum(is.na(x))
if(relative){
na_count <- na_count / length(x)
}
return(na_count)
}Všimněme si, že oproti předchozí verzi, jsme v naší funkci udělali několik změn. Zaprvé jsme přidali argument relative, jehož výchozí hodnotu jsme nastavili na FALSE (ve výchozím nastavení tedy funkce počítá absolutní počet chybějících hodnot). Dále jsme přidali blok začínající funkcí if(). Tato funkce zkontroluje, jestli je hodnota argumentu relative rovná TRUE a pokud ano, vydělí počet chybějících hodnot celkovou délkou proměnné x. Funkci používáme tak, jak jsme zvyklí:
countries %>%
summarise(across(.cols = everything(),
.fns = ~count_na(., relative = TRUE))) %>%
pivot_longer(cols = everything(),
values_to = "missings_count")# A tibble: 17 × 2
name missings_count
<chr> <dbl>
1 country 0
2 code 0
3 gdp 0.0789
4 population 0.0263
5 area 0
6 eu_member 0
7 postsoviet 0
8 life_exp 0.0263
9 uni_prc 0.0789
10 poverty_risk 0.132
11 material_dep 0.132
12 hdi 0
13 foundation_date 0
14 maj_belief 0
15 dem_index 0.0263
16 di_cat 0.0263
17 hd_title_name 0 28.1.2 Vlastní ggplot2 tématika
O něco komplexnější, ale také velmi častou vlastní funkcí je vlastní tématika pro grafy vytvoření balíčkem ggplot2. V praxi se často dostaneme do situací, kdy je třeba aby všechny naše grafy měli jednotný vzhled. Vypisovat pokaždé ty samé argumenty do funkce theme() je ale zdlouhavé a kopírování zbytečně prodluže skript. Vytvoříme si proto vlastní tématiku a formátování grafů se tak stane záležitostí na jeden řádek.
Ideální je využít již existující tématiku jako základ a pouze upravit části, se kterými nejsme spokojení. Stejně jako v předchozím případě vytvoříme novou funkci pomocí function(). Jako základ použijeme theme_light(), na kterou navážeme funkcí theme() s našimi vlastními argumenty:
theme_scooby <- function() {
theme_light() +
theme(plot.background = element_rect(fill = "#fee8c8"),
panel.background = element_rect(fill = "#fee8c8"),
text = element_text(family = "Calibri", size = 12),
title = element_text(size = 16),
legend.position = "bottom")
}Jakmile je naše tématika vytvořená, můžeme ji přidat ke grafům tak, jak jsme zvyklí:
ggplot(countries,
mapping = aes(x = hdi, y = life_exp)) +
geom_point() +
labs(title = "Tohle je naše nová tématika!",
x = "Index lidského rozvoje",
y = "Naděje na dožití") +
theme_scooby()Warning: Removed 1 row containing missing values or values outside the scale range
(`geom_point()`).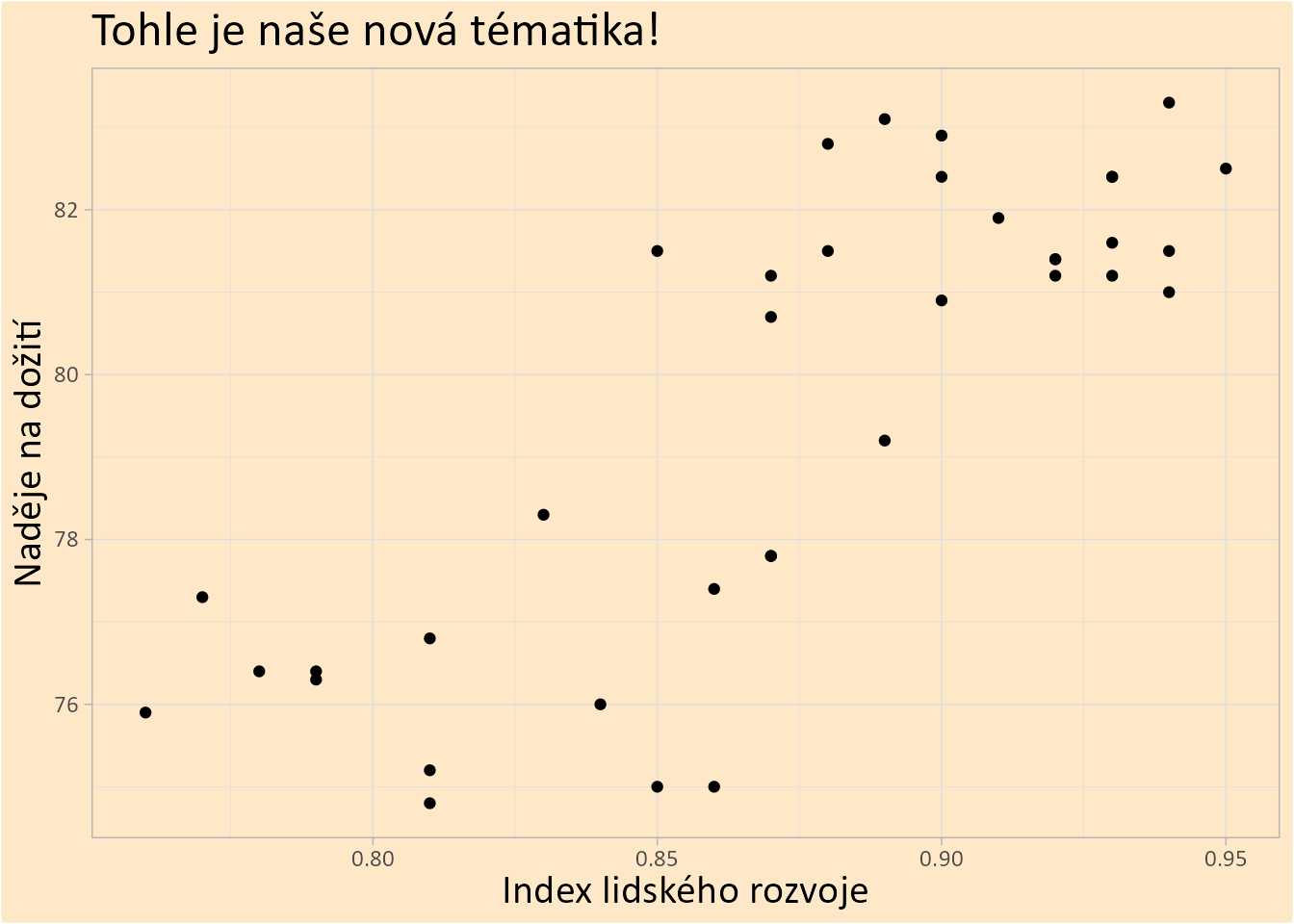
28.1.3 Graf pro likertovské položky
Nejkomplexnějším příkladem vlastní funkce, který si ukážeme, je vytvoření grafu pro baterii likertovských položek. Přestože vytvoření takového grafu je pomocí ggplot2 možné, jde o poměrně zdlouhavý proces. Jako příklad si můžeme ukázat vizualizaci položek týkajících se postojů veřejnosti o válce na Ukrajině. Data pochází z dotazníkového šetření Centra pro průzkum veřejného mínění z března 2022. Data jsou rozdělena do dvou dataframů. První z nich, ukraine, obsahuje odpovědi respondentů a druhý, ukraine_labels, obsahuje zjednodušené znění jednotlivých položek.
ukraine <- read_rds("data-raw/ukraine.rds")
ukraine_labels <- read_rds("data-raw/ukraine_labels.rds")Pro vytvoření grafu popisující postoje občanů k různým formám zapojení zemí do války vypadá následovně:
library(RColorBrewer)
library(scales)
likert_palette <- c("grey70", brewer.pal(4, "RdYlGn"))
ukraine %>%
select(starts_with("PL_5")) %>%
pivot_longer(cols = everything(),
names_to = "item",
values_to = "response") %>%
left_join(ukraine_labels, by = "item") %>%
count(label, response) %>%
filter(!is.na(response)) %>%
group_by(label) %>%
mutate(freq = n / sum(n),
freq_label = percent(freq, accuracy = 1),
positive = sum(freq[response %in% c("rozhodně by mělo", "spíše by mělo") ])) %>%
ungroup() %>%
mutate(label = fct_reorder(label, positive),
response = fct_rev(response)) %>%
ggplot(aes(x = freq, y = label, label = freq_label, fill = response)) +
geom_col() +
geom_text(position = position_stack(vjust = 0.5),
color = "white",
size = 3) +
scale_x_continuous(labels = percent_format()) +
scale_fill_manual(values = likert_palette) +
labs(x = element_blank(),
y = element_blank(),
fill = element_blank(),
title = "Jaké kroky by podle vás mělo podniknout mezinárodní společenství tváří v tvář\nválce na Ukrajině? Mělo by...") +
theme_minimal() +
theme(legend.position = c(0.3, -0.17),
panel.grid.major.y = element_blank(),
plot.title.position = "plot",
plot.margin = unit(c(0,0,3.5,0), 'lines')) +
guides(fill = guide_legend(label.position = "bottom",
keywidth = 5,
reverse = TRUE,
direction = "horizontal"))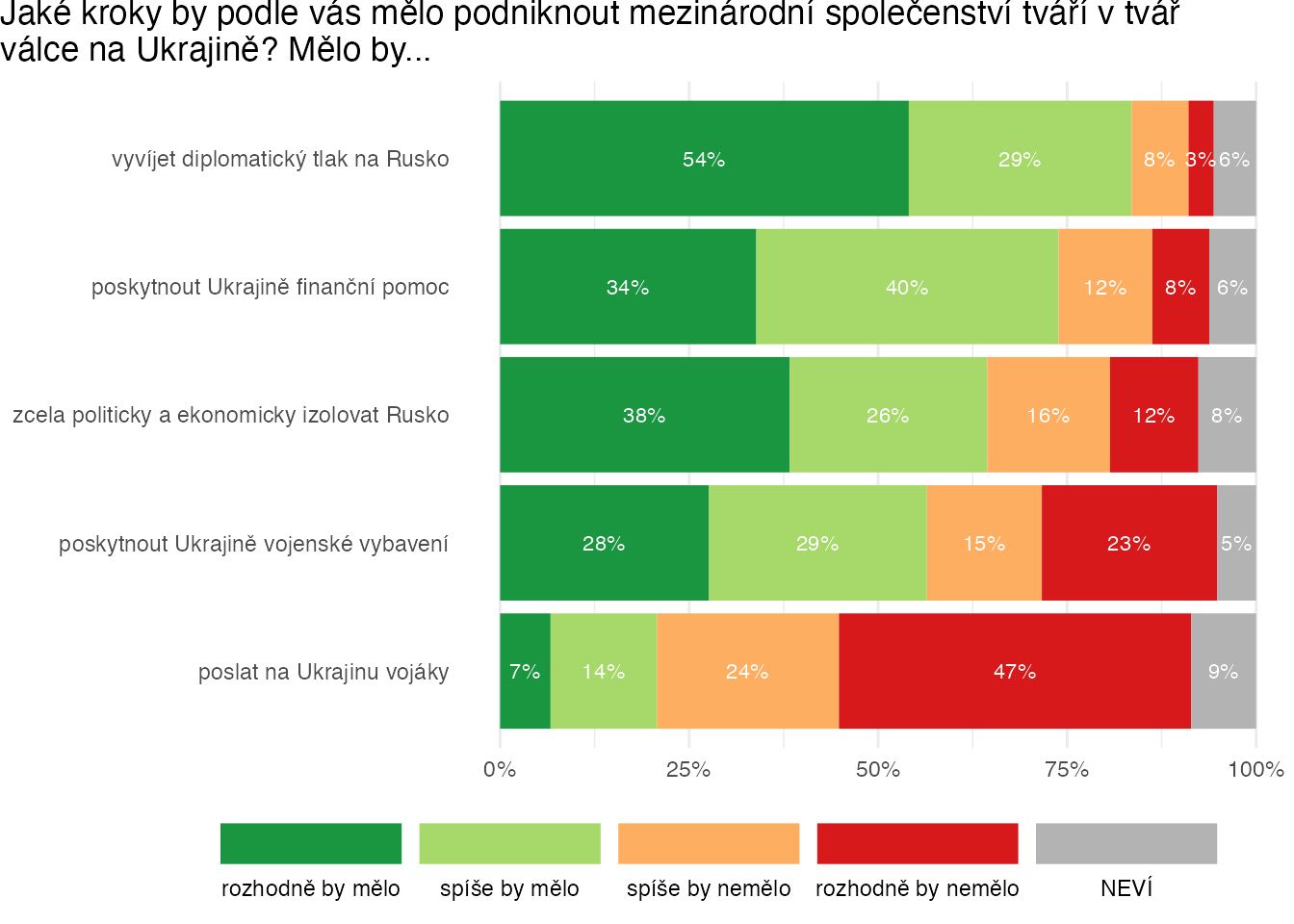
Uf… asi si dokážeme představit, že použít takto monstrózní kus kódu opakovaně je nejen otravné, ale i recept na to něco zkazit. Naštěstí pro nás, většina kódu zůstané při každém použití stejná. Jediné, co se bude měnit jsou 1) použitá data, 2) barevná paleta, 3) odpovědi, podle kterých jsou položky seřazeny, 4) název a 5) dataframe obsahující znění položek. Vytvořme si funkci plot_likert, která tento graf udělá za nás:
plot_likert <- function(data, color_palette, order_by, title, var_labels) {
data %>%
pivot_longer(cols = everything(),
names_to = "item",
values_to = "response") %>%
left_join(var_labels, by = "item") %>%
count(label, response) %>%
filter(!is.na(response)) %>%
group_by(label) %>%
mutate(freq = n / sum(n),
freq_label = percent(freq, accuracy = 1),
positive = sum(freq[response %in% order_by ])) %>%
ungroup() %>%
mutate(label = fct_reorder(label, positive),
response = fct_rev(response)) %>%
ggplot(aes(x = freq, y = label, label = freq_label, fill = response)) +
geom_col() +
geom_text(position = position_stack(vjust = 0.5),
color = "white",
size = 3) +
scale_x_continuous(labels = percent_format()) +
scale_fill_manual(values = color_palette) +
labs(x = element_blank(),
y = element_blank(),
fill = element_blank(),
title = title) +
theme_minimal() +
theme(legend.position = c(0.3, -0.17),
panel.grid.major.y = element_blank(),
plot.title.position = "plot",
plot.margin = unit(c(0,0,3.5,0), 'lines')) +
guides(fill = guide_legend(label.position = "bottom",
keywidth = 5,
reverse = TRUE,
direction = "horizontal"))
}Definice naší funkce vypadá téměř identicky jako původní kód, pět výše zmíněných částí jsme strategicky nahradili argumenty naší funkce. Jakmile je funkce vytvořené, je možné jí aplikovat na data. Kód pro vytvoření grafu se smrknul z třiceti řádků na šest:
ukraine %>%
select(starts_with("PL_5")) %>%
plot_likert(color_palette = likert_palette,
order_by = c("rozhodně by mělo", "spíše by mělo"),
title = "Jaké kroky by podle vás mělo podniknout mezinárodní společenství tváří v tvář\nválce na Ukrajině? Mělo by...",
var_labels = ukraine_labels)Warning: `label` cannot be a <ggplot2::element_blank> object.
`label` cannot be a <ggplot2::element_blank> object.
`label` cannot be a <ggplot2::element_blank> object.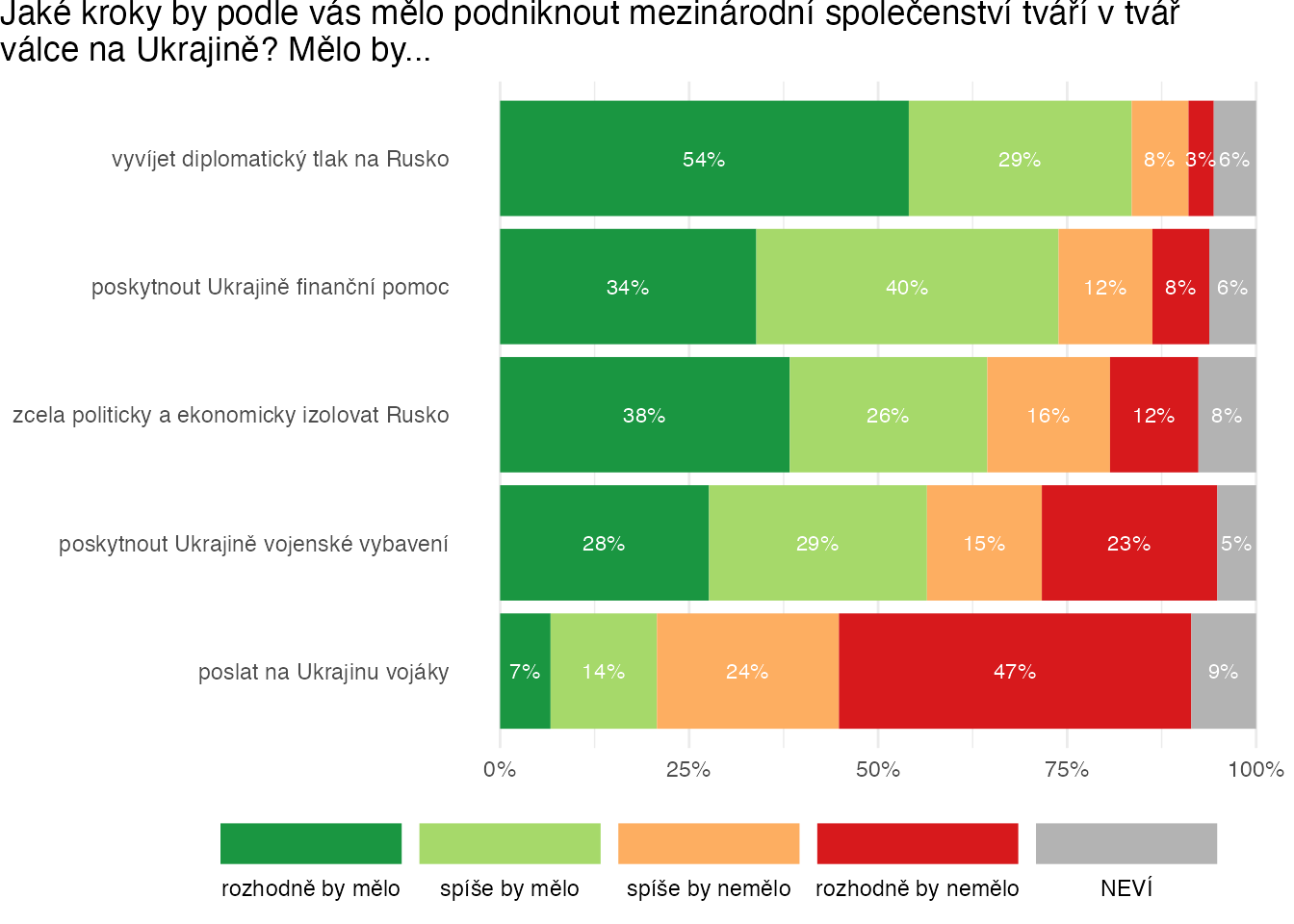
Naší funkci můžeme stejně jednoduše aplikovat na druhou baterii v datech, týkající se vnímané hrozby použití atomových zbraní:
likert_palette2 <- c("grey70", rev(brewer.pal(4, "RdYlBu")))
ukraine %>%
select(starts_with("PL_6")) %>%
plot_likert(color_palette = likert_palette2,
order_by = c("velmi se obává", "trochu se obává"),
var_labels = ukraine_labels,
title = "Obáváte se, že Rusko může použít jaderné zbraně…")Warning: `label` cannot be a <ggplot2::element_blank> object.
`label` cannot be a <ggplot2::element_blank> object.
`label` cannot be a <ggplot2::element_blank> object.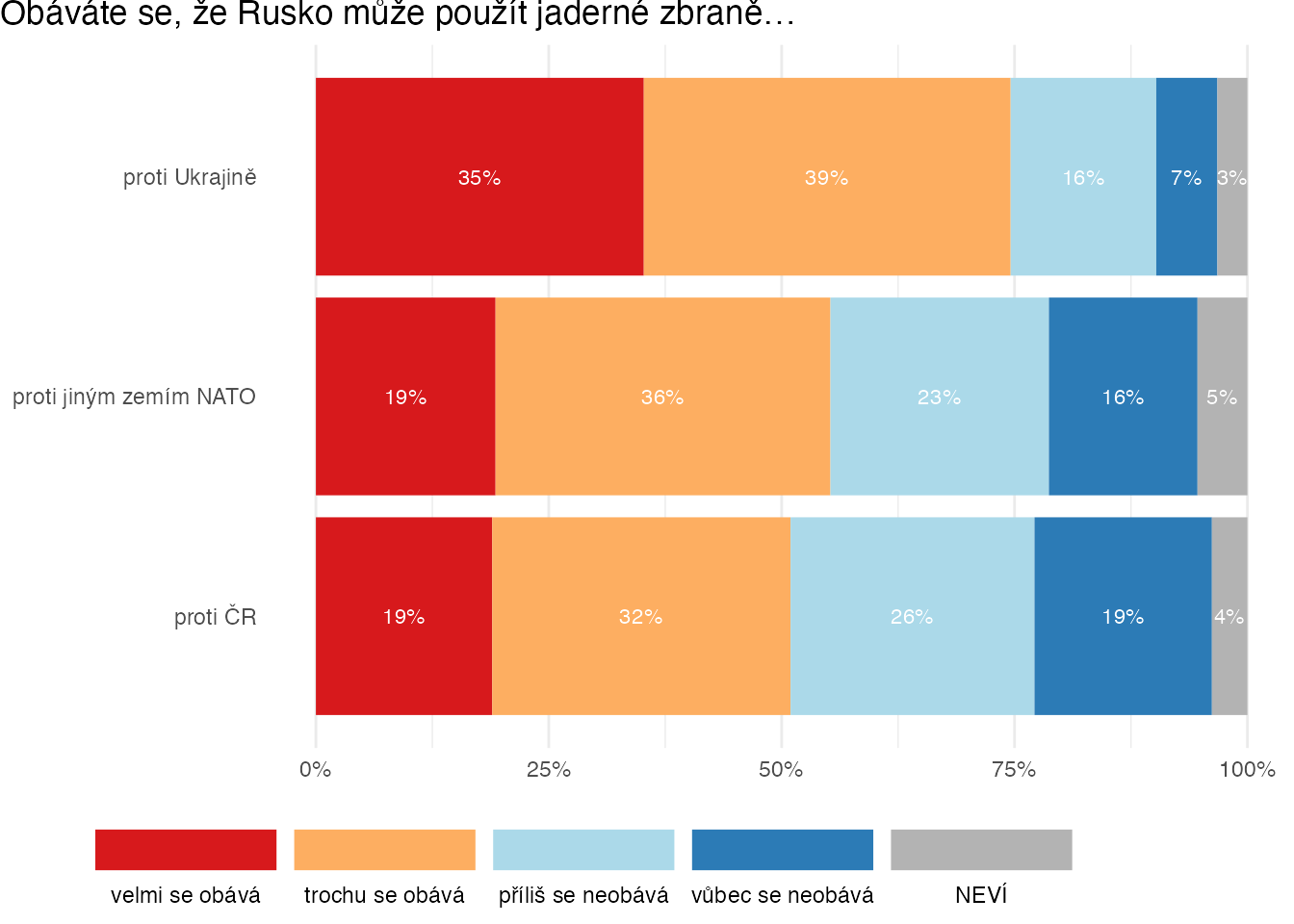
Jak je vidět, vytvořením vlastní funkce si můžeme výrazně ulehčit práci, nemluvě o tom, že tím náš kód uděláme čitelnější a robustnější.
28.2 Export vlastních funkcí
Vlastní funkce nám výrazně ulehčují (a urychlují!) práci. Jak si je ale efektivně uložit pro pozdější použití? Možnosti máme v podstatě dvě - uložit si naše funkce do samostatného skript a vytvořit si vlastní balíček.
Uchovávat si naše funkce ve vlastním skriptu je jednoduším rešením. Stačí si vytvořit nový R skript a zkopírujete si do něj definice vašich funkcí. Skript si můžete pojmenovat podle libosti, například custom-functions.R. Obsahem toho skriptu by pro pořádek měli být pouze definice funkcí:
## Vlastní tématika pro ggplot2
theme_scooby <- function() {
theme_light() +
theme(plot.background = element_rect(fill = "#fee8c8"),
panel.background = element_rect(fill = "#fee8c8"),
text = element_text(family = "Calibri", size = 12),
title = element_text(size = 16),
legend.position = "bottom")
}
## Výpočet chybějících hodnot
count_na <- function(x, relative = FALSE) {
na_count <- sum(is.na(x))
if(relative){
na_count <- na_count / length(x)
}
return(na_count)
}Jakmile máme skript připravený, naše funkce jsou na dosah ruky i poté, co zrestartujeme R. Stačí na začátku analýzu využít funkci source(), pomocí které lze spustit Rkovský skript z jiného Rkovského skriptu. Skript pro analýzu dat poté může začínat nějak takhle:
library(tidyverse) # Nahraje funkce z balíčků tidyverse
source("custom-functions.R") # Nahraje námi vytvořené funkce ze skriptu custom-functions.R
countries <- read_csv("data-raw/countries.csv")S pomocí source() se v jistém smyslu můžeme ke skriptu custom-functions.R chovat jako k našemu vlasntímu pseudo-balíčku!
Výše popsaný postup je jednoduchý a v mnoha případech dostatečný, zvlášť pokud tušíme, že naše funkce nebudeme používat ve více, než jednom projektu. I přesto se ale někdy vyplatí vytvořit plnohodnotný balíček. To nejen ulehčí příštup k našim funkcím našim kolegům, ale umožní nám také připravit pro ně (a pro nás) nápovědu k funkcím nebo příklady použití. U plnohodnotných balíčků je také jednoduší provádět automatické kontroly funkčnosti, abychom měli jistotu, že funguje jak má.
Vytváření vlastního balíčku je bohužel nad rámec této učebnice, nemusíte ale zoufat. Excelentí učebnící je R packages, která vás provede všemi kroky vytváření balíčků. A možná zjistíte, že vytváření balíčků je mnohem jednoduší, než se na první pohled může zdát!