breed_traits <- read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2022/2022-02-01/breed_traits.csv')
breed_ranks <- read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2022/2022-02-01/breed_rank.csv')13 Spojování dataframů
V ideálním světě by všechna data potřebná pro naši analýzu byla připravena v jednom úhledném datasetu. Praxe je ovšem mnohem krutější a nutí nás si data čistit svépomocí. Jednou z častých nutností je spojovat větší počet dílčích datasetů dohromady, k čemuž nám poslouží sada funkcí *_join().
13.1 Spojovací funkce rodiny JOIN
Funkce rodiny JOIN použijeme, pokud máme dva a více datasetů, ve kterých pozorujeme stejné (nebo zčásti stejné) subjekty, ale v každém souboru pro ně máme k dispozici jiné údaje. Jako ilustrativní příklad využijeme dva datasety, kde jednotlivá porozování (řádky) představují jednotlivá psí plemena. Ve sloupcích jsou v jednom z nich hodnoty pro jednotlvé vlastnosti těchto plemen (dataset “traits”), ve druhém pak pořadí jejich oblíbenosti (asi v USA) ve vybraných letech. Hned nás napadne, že bychom možná rádi měli hodnoty vlastností a pořadí oblíbenosti propojeny do jednoho datového souboru. O tom je tato kapitola. Abychom situaci trochu zkomplikovali, v každém datasetu jsme několik plemen vymazali. Takže z většiny se oba datasety překrývají, ale každý také obsahuje některá plemena, která ten druhý neobsahuje.
V takové situaci můžeme spojovat dva datasety více způsoby, které jsou naznačeny na následujícím obrázku.
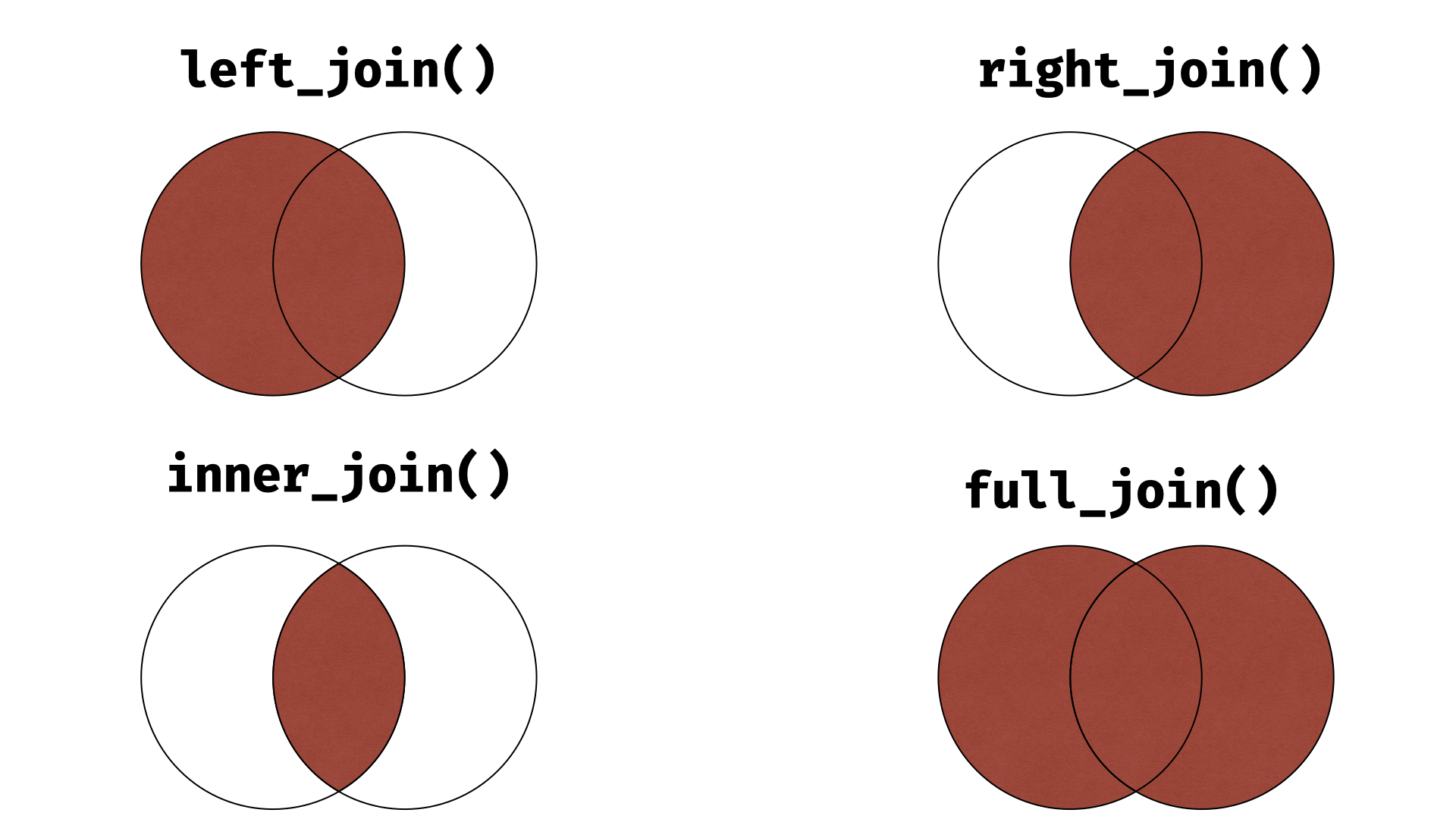
Ať už se rozhodneme pro kteroukoliv metodu propojení, vždy potřebujeme zvolit tzv. klíč, tedy jednu nebo více proměnných, podle kterých budeme data spojovat. V našem ilustrativním příakladu to bude plemeno psa.
Nyní už k jednotlivým metodám spojování: První z nich, left_join(), se podívá, které řádky (resp. která psí plemena) v prvním specifikovaném datasetu se vyskytují také ve druhém datasetu. Proměnné pozorované pro tato plemena pak “připojí” k proměnným v prvním datasetu. Pokud jsou nějaké řádky (nějaká plemena) přítomny jen ve druhém (pravém) datasetu, jsou ztraceny. Pokud jsou nějaké jen v prvním z nich, zůstanou zachovány, ale proměnné z druhého datasetu pro ně přirozeně budou mít chybějící hodnoty. Analogickou funkcí je poté right_join(), která zachová pouze řádky s hodnotami klíče (s psími plemeny) nacházejícími se v druhém dataframu. Následně inner_join() je nejpřísnější z funkcí a při spojení dataframů zachová pouze řádky s hodnotami nacházejícími se v obou datasetech. Naopak funkce full_join() je nejliberálnější a zachová při spojení všechna data.
Nyní už slibovaná ukázka na datech ze světa psů, konkrétně datech z American Kennel Club. Původní dva dasety jsme získali z otevřené výzvy v rámci Tidytuesday. Pro naše účely jsme data mírně upravili, importovat je lze přímo z webových stránek
První z těchto datasetů obsahuje hodnocení o vlastnostech psích plemen jak byly hodnoceny členy klubu. Vlastností tu najdeme celou řadu, od délky kožichu po přátelskost nebo slintavost. Druhý dataset obsahuje informace o popularitě plemen za posledních zhruba 10 let, plus pár popisných odkazů:
names(breed_traits) [1] "Breed" "Affectionate With Family"
[3] "Good With Young Children" "Good With Other Dogs"
[5] "Shedding Level" "Coat Grooming Frequency"
[7] "Drooling Level" "Coat Type"
[9] "Coat Length" "Openness To Strangers"
[11] "Playfulness Level" "Watchdog/Protective Nature"
[13] "Adaptability Level" "Trainability Level"
[15] "Energy Level" "Barking Level"
[17] "Mental Stimulation Needs" names(breed_ranks) [1] "Breed" "2013 Rank" "2014 Rank" "2015 Rank" "2016 Rank" "2017 Rank"
[7] "2018 Rank" "2019 Rank" "2020 Rank" "links" "Image" Všimněme si, že oba datasety obsahují proměnnou Breed, tedy plemeno psa. To bude naším klíčem, tedy proměnou, pomocí které spojíme oba dataframy dohromady. Důvodem, proč nejsou oba datasety spojené už od začátku, je že ne všechna plemena obsažená v breed_traits se umístila v ročním hodnocení, a chybí tedy v breed_ranks. Při spojování dat je tedy na nás, jak se touto komplikací vypořádáme.
První možností je vzít dataframe breed_traits a přilepit k němu breed_ranks, pomocí funkce left_join(). Výsledkem bude dataframe, který obsahuje všechny informace z breed_traits a pokud se některé plemeno neumístilo v žebříčku z bree_ranks, bude mít v proměnných hodnocení chybějící hodnotu:
x <- left_join(breed_traits, breed_ranks, by = "Breed")# A tibble: 10 × 27
Breed Affectionate With Fa…¹ Good With Young Chil…² `Good With Other Dogs`
<chr> <dbl> <dbl> <dbl>
1 Spaniel… 5 3 3
2 Spaniel… 5 5 4
3 Wirehai… 5 5 3
4 St. Ber… 5 5 3
5 America… 5 5 3
6 Norwich… 5 5 3
7 Old Eng… 5 5 3
8 Pointer… 5 3 3
9 Azawakhs 3 3 3
10 Keeshon… 5 5 5
# ℹ abbreviated names: ¹`Affectionate With Family`, ²`Good With Young Children`
# ℹ 23 more variables: `Shedding Level` <dbl>, `Coat Grooming Frequency` <dbl>,
# `Drooling Level` <dbl>, `Coat Type` <chr>, `Coat Length` <chr>,
# `Openness To Strangers` <dbl>, `Playfulness Level` <dbl>,
# `Watchdog/Protective Nature` <dbl>, `Adaptability Level` <dbl>,
# `Trainability Level` <dbl>, `Energy Level` <dbl>, `Barking Level` <dbl>,
# `Mental Stimulation Needs` <dbl>, `2013 Rank` <dbl>, `2014 Rank` <dbl>, …Všimněme si, že například němečtí ovčáci nebyli hodnoceni a u proměnných 2013 Rank až 2019 Rank tedy mají chybějící hodnotu. Naopak pro buldoky jsou k dispozici k dispozici všechna data.
Alternativou k left_join() je funkce right_join(). Ta provede velmi podobnou operaci, jako jsme viděli výše, výchozím dataframem zde ale bude breed_ranks.
right_join(breed_traits, breed_ranks, by = "Breed")# A tibble: 10 × 27
Breed Affectionate With Fa…¹ Good With Young Chil…² `Good With Other Dogs`
<chr> <dbl> <dbl> <dbl>
1 Spaniel… 5 3 3
2 Wirehai… 5 5 3
3 St. Ber… 5 5 3
4 America… 5 5 3
5 Norwich… 5 5 3
6 Pointer… 5 3 3
7 Azawakhs 3 3 3
8 Keeshon… 5 5 5
9 Chihuah… 4 1 3
10 Spanish… 5 4 3
# ℹ abbreviated names: ¹`Affectionate With Family`, ²`Good With Young Children`
# ℹ 23 more variables: `Shedding Level` <dbl>, `Coat Grooming Frequency` <dbl>,
# `Drooling Level` <dbl>, `Coat Type` <chr>, `Coat Length` <chr>,
# `Openness To Strangers` <dbl>, `Playfulness Level` <dbl>,
# `Watchdog/Protective Nature` <dbl>, `Adaptability Level` <dbl>,
# `Trainability Level` <dbl>, `Energy Level` <dbl>, `Barking Level` <dbl>,
# `Mental Stimulation Needs` <dbl>, `2013 Rank` <dbl>, `2014 Rank` <dbl>, …V tomto případě již plemena jako zlatý retrívr nebo německý ovčák ve výsledném dataframu nenajdeme vůbec, protože nejsou obsažena v dataframu breed_ranks.
TipJak napravo, tak nalevo
Výsledek funkce left_join(breed_traits, breed_ranks) je ekvivalentní funkci right_join(breed_ranks, breed_traits).
Pro zachování pouze plemen, která jsou obsažena v obou dataframech, lze aplikovat funkci inner_join(). Výsledný dataframe bude mít mnohem méně řádků, než ty předchozí, pouze 49, protože většina plemen není v dataframu breed_ranks:
inner_join(breed_traits, breed_ranks, by = "Breed")Poslední verzí je permisivní outer_joint(), která spojí oba dataframy a zachová přitom všechny řádky:
full_join(breed_traits, breed_ranks, by = "Breed")13.2 Kterou spojovací funkci použít?
Každá z výše zmíněných funkcí se hodí pro jinou situaci. Která je ta pravá? Pokud je hlavním cílem naší práce analýza charakteristik jednotlivých plemen, bude pro nás nejužitečnější left_join(breed_traits, breed_ranks). Na druhou stranu, pokud by pro naši analýzu bylo stěžejní roční hodnocení, uplatili bychom spíše right_join(breed_traits, breed_ranks), protože plemena, který nebyla hodnocena, pro nás nejsou zajímavá. Pro analýzu vztahů mezi charakteristikami a hodnocením pro nás budou užitečná pouze plemena, pro která máme k dispozici všechny informace, a ty bychom získali pomocí inner_join(breed_traits, breed_ranks). Nakonec, pokud by naším cílem bylo jen datasety spojit, aniž bychom přišli o jakkýkoliv data, například pro jejich uskladnění, využili bychom full_join(breed_traits, breed_ranks).